文本对抗样本检测的随机替换和投票
https://arxiv.org/pdf/2109.05698.pdf
摘要
这篇工作提出了一种对抗样本检测模块,针对检测出数据集中通过单词替换生成的对抗样本。
方法
Motivation
对一个文本中的单词进行替换生成了预测和标签不一致的对抗样本,这个替换后的序列中,每个单词相互影响其他单词(相互交互),共同影响模型的判断,所以,受现有基于输入预处理的防御(Wang et al. 2021a; Zhou et al. 2021)的启发,我们观察到随机同义词替换可以破坏这种相互交互并以高概率消除对抗性扰动。
为了验证我们的假设,我们首先使用 Textfooler 攻击(Jin 等人,2020 年)对来自 AG 新闻测试集的 1,000 个随机采样文本生成对抗性示例,这些文本由 Word-CNN 正确分类(Kim 2014)。
为了打破替换序列中单词之间的交互,我们首先将良性样本(Benign)或对抗性示例(Adversarial)中的单词随机屏蔽为未知 (“UNK”) 标记,表示为 UNK Benign 或 UNK Adversarial,以不同的比率将这些处理过的文本提供给模型。如图 1 所示:
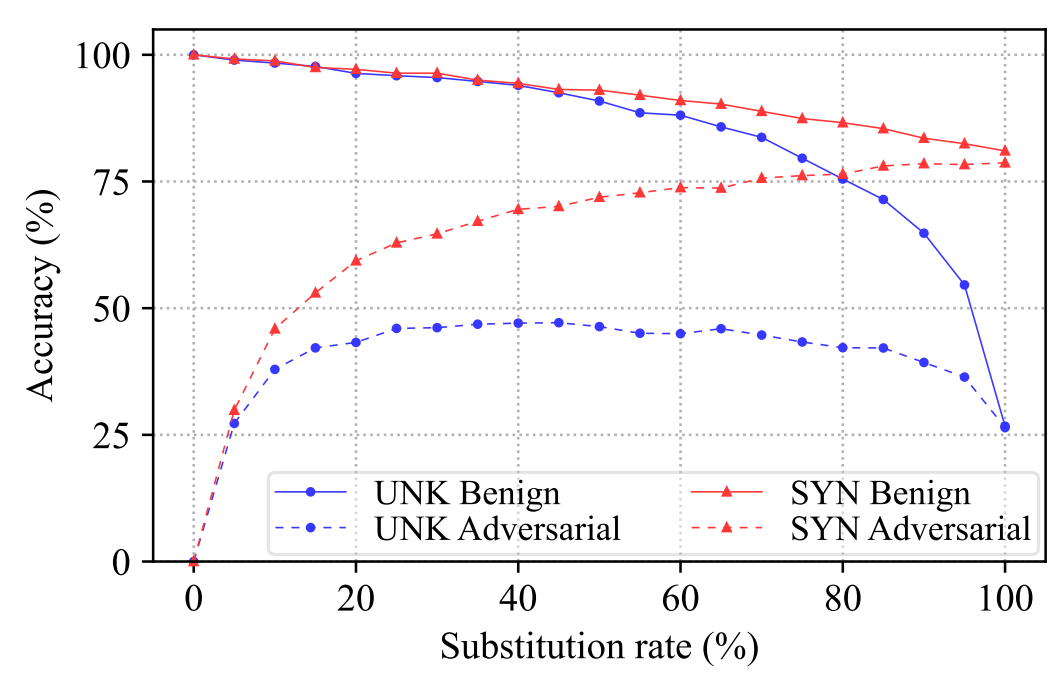
图一:在来自 AG 的 Word-CNN 新闻测试集的1,000 个正确分类的样本上进行评估,良性样本(Benign)准确率 100%,对应的对抗样本(Adversarial)准确率 0%,当我们用一定比率去替换样本中的单词(蓝色代表替换为 ‘UNK’,红色代表替换为同义词),发现准确率对应的变化曲线
- 当我们在良性文本中屏蔽 40% 的单词时,分类准确率仍然超过 90%,显示了模型对这种随机掩码的稳定性和鲁棒性。
- 相比之下,当我们屏蔽更多词时,对抗样本的分类准确度显着提高,当屏蔽 40% 的词时,我们可以恢复 50% 的对抗样本。这验证了我们的假设,即如果我们(通过随机掩码)成功打破替换序列中单词的相互交互,我们就可以消除对抗性扰动(acc从0 唤醒到 40)。
- 而当我们尝试用同义词随即替换单词(而非 UNK 时),如图 1 所示,我们发现在良性样本或对抗样本中随机用同义词替换单词,表示为 SYN Benign 或 SYN Adversarial,可以持续且显着地提高对抗对抗样本的鲁棒准确率,同时在各种替代率下的良性样本上保持较高的准确率 ,这进一步验证了我们的假设。
基于上述观察,我们提出了一种新的文本对抗样本检测方法,称为 RS&V,该方法将输入文本中的单词随机替换为其同义词,以有效检测对抗样本,恢复输入对抗样本的正确标签。具体做法如下:
- 对于一个输入文本 x
- 随即替换一些词 wi ∈ x(用它的任意同义词 w^i)
- 得到 k 种样本 { x1, x2, · · · , xk }
- 累积 k 个处理样本的 logits 输出(vote),如果 x 的预测与 k 个样本投票的预测不一致,则将 x 视为对抗性示例。
实验
对比基线:
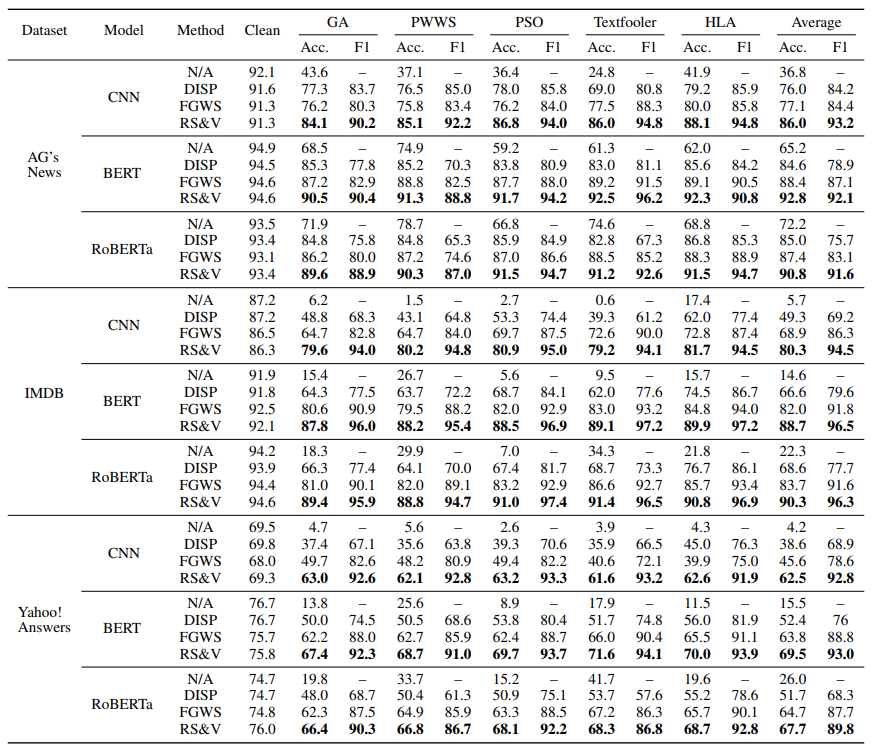
对抗方法: GA (Alzantot et al. 2018)、PWWS (Ren et al. 2019)、PSO (Zang et al. 2020)、Textfooler (Jin et al. 2018) . 2020)和 HLA(Maheshwary、Maheshwary 和 Pudi 2021)。
检测方法:DISP (Zhou et al. 2019) 训练一个扰动鉴别器来识别被扰动的标记和一个嵌入估计器来重建原始文本。FGWS (Mozes et al. 2021) 用字典中最常用的同义词替换低频词,以消除对抗性扰动。
个人总结
其实这篇文章的设计灵感主要来源于针对同义词替换对抗,如果我们随机用同义词替换样本里的词,会导致在良性样本上趋于一致性,而在对抗样本上反映出唤醒(不一致性),为了使这种不一致更有说服力,用了投票机制,通过检测这种不一致来检测对抗样本,并更新他们的标签,从而达到纠正对抗样本的效果
这篇文章引用到去噪的工作中,可以针对 ‘词替换’ 类型的token级噪声,随即引入同义词以检测预测是否具有一致性,来检查是否为带噪输入,可以参考为一种纠错模块。结合之前的鲁棒性训练一起使用(训练时用鲁棒性训练,测试时带入纠错模块)。


![[COLING 2018] Modeling Semantics with Gated Graph Neural Networks for KBQA 阅读笔记](https://img-blog.csdnimg.cn/9d909061f81a4c58a4cd7c9a0c40e1d4.png)