
回顾pandas的一些内容
pandas是一个用于数据分析的库,必备库,官网:pandas documentation
pandas最核心的两个数据结构:Series、DataFrame
先看看pandas安装是否成功
import pandas as pd
pd.__version__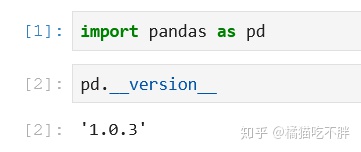
Series
用来表示一维数据结构,和数组类似,由index和value组成
class
pandas.Series(
data=None,
index=None,
dtype=None,
name=None,
copy=False,
fastpath=False)
s = pd.Series([3,5,7])创建一个Series对象

0,1,2就是默认初始化的索引,3,5,7是我们传入的data
我们当然也可以传入index
s = pd.Series([3,5,7], index=['one', 'two', 'three'])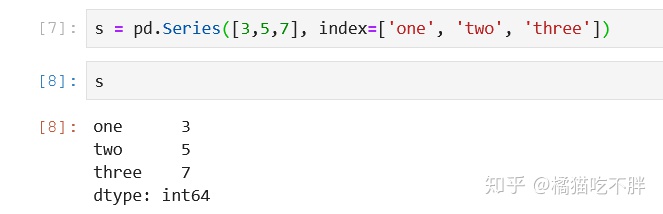
我们可以查看Series的index和value
s.index
s.values
这里,我们可以发现,index和value都是有dtype的,就都是有类型的
筛选
这里和numpy很像,可以使用索引来选择指定元素
这里可以使用index做筛选,也可以使用索引,这个index理解为标签
s['one']
s['two']
s[1]
s[1:2]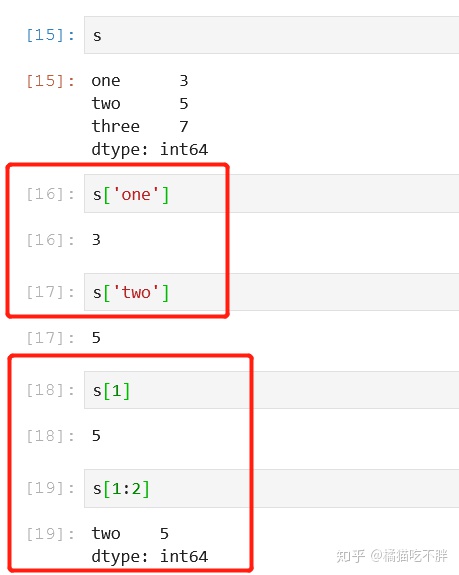
在numpy中提到的一些筛选方法,Series中同样适用
比如,布尔数组筛选
s[s>5]
基本的四则运算
s+1
s*2
常用函数
获取唯一值:
Series.unique()
返回series中的唯一值
s = pd.Series([1,3,3,4,5,5,7])
s.unique()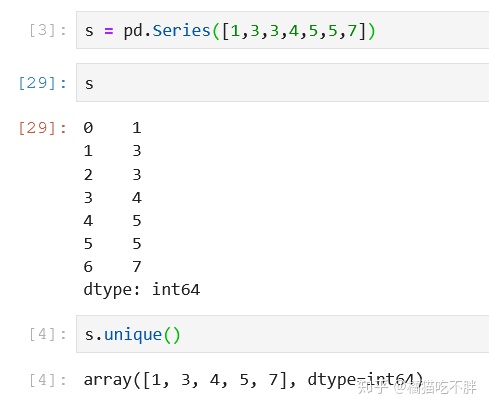
还有一个类似的函数
Series.value_counts(
normalize=False,
sort=True,
ascending=False,
bins=None,
dropna=True)
返回的也是唯一值,但是多了唯一值出现的次数
s.value_counts()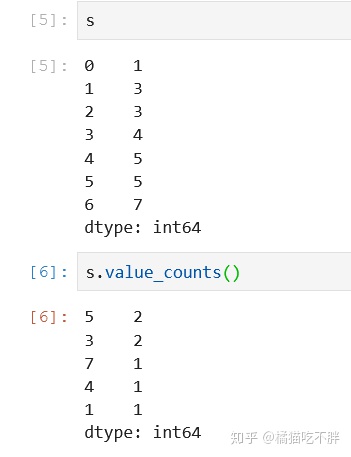
Series.isin(
values)
判断所属关系,是否包含指定的元素
s = pd.Series(['lama', 'cow', 'lama', 'beetle', 'lama', 'hippo'], name='animal')
s.isin(['cow', 'lama'])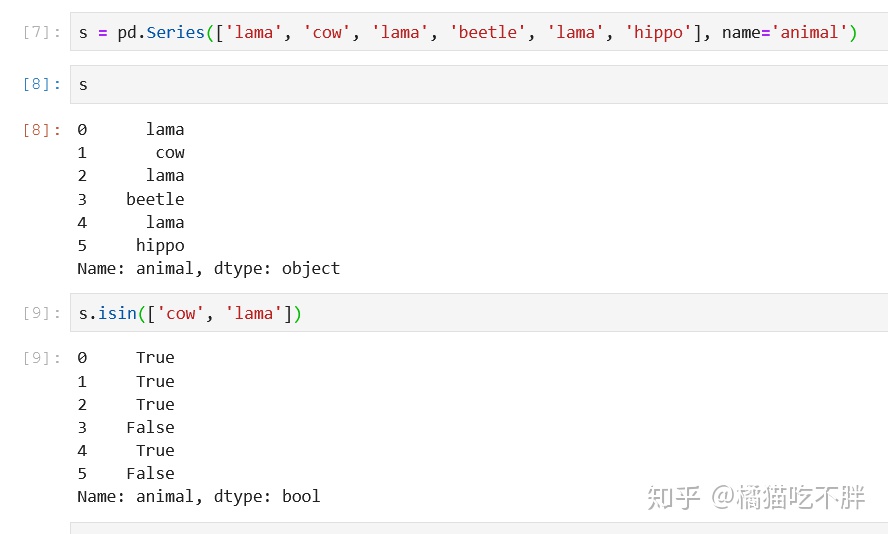
这里返回的是一个Boolean数组,正好可以用来筛选数据
s[s.isin(['cow', 'lama'])]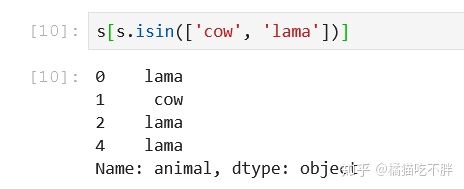
Series.isna()Series.isnull()
用来判断是否包含NaN(Not a Number)
s = pd.Series(['aaa', 'bbb', np.NaN])
s.isna()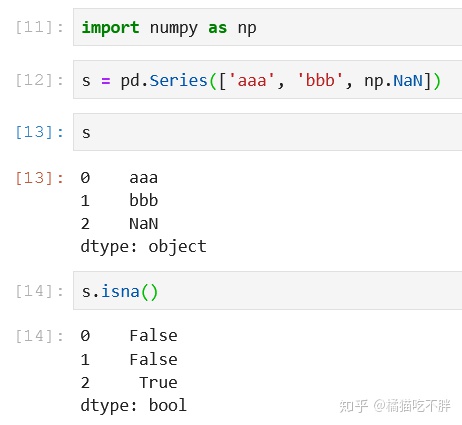
相对应的还有
Series.notna()Series.notnull()
上述4个函数返回的也是Boolean数组,都可以用来筛选
DataFrame
DataFrame就是将Series拓展到多维,和日常使用的Excel非常像
DataFrame除了有index,还有column,就像行索引和列索引
class
pandas.DataFrame(
data=None,
index=None,
columns=None,
dtype=None,
copy=False)
df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
df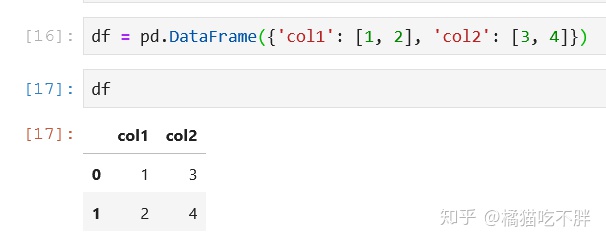
这里,会将key自动识别为column,自动生成index
我们也可以直接传入data,指定index和column
df = pd.DataFrame([[1,2,3],[4,5,6]], columns=['a','b','c'], index=['one','two'])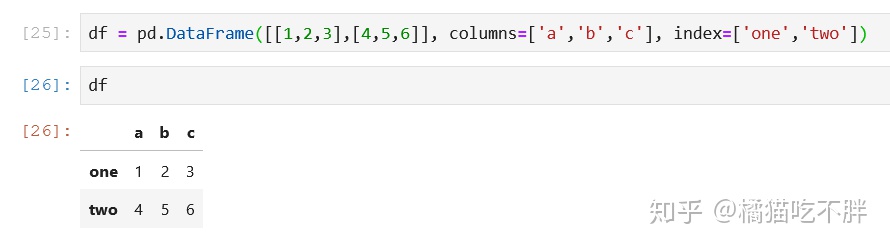
基础信息
df.index
df.columns
df.values
筛选数据
可以使用columns直接进行筛选
df['a']
df[['a','b']]


